
Results Where Data is Normally Distributed and Variance is Known or Unknown
- Whenever variance of a population (σ2) is known, the z-test is the preferred alternative to test a hypothesis of the population mean (μ). To compute the test statistic, standard error is equal to population standard deviation / sq. root of sample size. For example, with a population variance of 64 and a sample size of 25, standard error is equal to (64)1/2/(25)1/2, or 1.6.
Example: Test Statistic
Suppose that in this same case we have constructed a hypothesis test that the mean annual return is equal to 12%; that is, we have a two-tailed test, where the null hypothesis is that the population mean = 12, and the alternate is that it is not equal to 12. Using a 0.05 critical level (0.025 for each tail), our rule is to reject the null when the test statistic is either below -1.96 or above +1.96 (at p = .025, z = 1.96). Suppose sample mean = 10.6.
Answer: Test statistic = (10.6 - 12)/1.6 = -1.4/1.6 = -0.875. This value does not fall below the rejection point, so we cannot reject the null hypothesis with statistical certainty. - When we are making hypothesis tests on a population mean, it's relatively likely that the population variance will be unknown. In these cases, we use a sample standard deviation when computing standard error, and the t-statistic for the decision rule (i.e. as the source for our rejection level). Compared to the z or standard normal, a t-statistic is more conservative (i.e. higher rejection points for rejecting the null hypothesis). In cases with large sample sizes (at least 30), the z-statistic may be substituted.
Example: Take a case where sample size is 16. In this case, the t-stat is the only appropriate choice. For the t-distribution, degrees of freedom are calculated as (sample size - 1), df = 15 in this example. In this case, assume we are testing a hypothesis that a population mean is greater than 8, so this will be a one-tailed test (right tail): null hypothesis is μ < 8, and the alternative is that μ > 8. Our required significance level is 0.05. Using the table for Student's t-distribution for df = 15 and p = 0.05, the critical value (rejection point) is 1.753. In other words, if our calculated test statistic is greater than 1.753, we reject the null hypothesis.
Answer: Moving to step 5 of the hypothesis-testing process, we take a sample where the mean is 8.3 and the standard deviation is 6.1. For this sample, standard error = s /n1/2 = 6.1/(16)1/2 = 6.1/4 = 1.53. The test statistic is (8.3 - 8.0)/1.53 = 0.3/1.53, or 0.196. Comparing 0.196 to our rejection point of 1.753, we are unable to reject the null hypothesis.
Note that in this case, our sample mean of 8.3 was actually greater than 8; however, the hypothesis test is set up to require statistical significance, not simply compare a sample mean to the hypothesis. In other words, the decisions made in hypothesis testing are also a function of sample size (which at 16 is low), the standard deviation, the required level of significance and the t-distribution. Our interpretation in this example is that the 8.3 from the sample mean, while nominally higher than 8, simply isn't significantly higher than 8, at least to the point where we would be able to definitively make a conclusion regarding the population mean being greater than 8.
Relative equality of population means of two normally distributed populations, where independent random sample assumed variances are equal or unequal
For the case where the population variances for two separate groups can be assumed to be equal, a technique for pooling an estimate of population variance (s2) from the sample data is given by the following formula (assumes two independent random samples):
Formula 2.37 Where: n1, n2 are samples sizes, and s12, s22 are sample variances. Degrees of freedom = n1 + n2 - 2 |
For testing equality of two population means (i.e. μ1 = μ2), the test statistic calculates the difference in sample means (X1 - X2), divided by the standard error: the square root of (s2/n1 + s2/n2).
Example: Population Means
Assume that the pooled estimate of variance (s2) was 40 and sample size for each group was 20. Standard error = (40/20 + 40/20)1/2 = (80/20) ½ = 2.
Answer: If sample means were 8.6 and 8.9, the t = (8.6 - 8.9)/2 = -0.3/2 = -0.15. Tests of equality/inequality are two-sided tests. With df = 38 (sum of samples sizes - 2) and if we assume 0.05 significance (p = 0.025), the rejection level is t < -2.024, or t > +2.024. Since our computed test statistic was -0.15, we cannot reject the null hypothesis that these population means are equal.
1. For hypothesis tests of equal population means where variances cannot be assumed to be equal, the appropriate test statistic for the hypothesis is the t-stat, but we can no longer pool an estimate of standard deviation, and the standard error becomes the square root of [(s12/n1) + (s22/n2)]. The null hypothesis remains μ1 = μ2, and the test statistic is calculated similar to the previous example (i.e. difference in sample means / standard error). Computing degrees of freedom is approximated by this formula
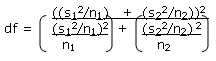 |
| Look Out! Note: Don't spend time memorizing this formula; it won't be required for the exam. Focus instead on the steps of hypothesis testing and interpreting results. |
The Paired-Comparisons Test
The previous example tested the equality or inequality of two population means, with a key assumption that the two populations were independent of each other. In a paired-comparisons test, the two populations have some degree of correlation or co-movement, and the calculation of test statistic takes account of this correlation.
Take a case where we are comparing two mutual funds that are both classified as large-cap growth, in which we are testing whether returns for one are significantly above the other (statistically significant). The paired- comparisons test is appropriate since we assume some degree of correlation, as returns for each will be dependent on the market. To calculate the t-statistic, we first find the sample mean difference, denoted by d:
d = (1/n)(d1 + d2 + d3 .... + dn), where n is the number of paired observations (in our example, the number of quarters for which we have quarterly returns), and each d is the difference between each observation in the sample. Next, sample variance, or (sum of all deviations from d )2/(n - 1) is calculated, with standard deviation (sd) the positive square root of the variance. Standard error = sd/(n)1/2.
For our mutual example, if our mean returns are for 10 years (40 quarters of data), have a sample mean difference of 2.58, and a sample standard deviation of 5.32, our test statistic is computed as (2.58)/((5.32)/(40)1/2), or 3.067. At 49 degrees of freedom with a 0.05 significance level, the rejection point is 2.01. Thus we reject the null hypothesis and state that there is a statistically significant difference in returns between these funds.
Hypothesis Tests on the Variance of a Normally Distributed Population
Hypothesis tests concerning the value of a variance (σ2) start by formulating the null and alternative hypotheses.
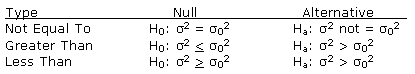 |
In hypothesis tests for the variance on a single normally distributed population, the appropriate test statistic is known as a "chi-square", denoted by χ2. Unlike the distributions we have been using previously, the chi-square is asymmetrical as it is bound on the left by zero. (This must be true since variance is always a positive number.) The chi-square is actually a family of distributions similar to the t-distributions, with different degrees of freedom resulting in a different chi-square distribution.
| Formula 2.38The test statistic is χ2 = (n - 1)*s2 σ02 |
Where: n = sample size, s2 = sample variance, σ02 = population variance from hypothesis
Sample variance s2 is refereed to as the sum of deviations between observed values and sample mean2, degrees of freedom, or n - 1
Example: Hypothesis Testing
Chi Squared Statistic
To illustrate a hypothesis test using the chi-square statistic, take an example of a fund that we believe has been very volatile relative to the market, and we wish to prove that level of risk (as measured by quarterly standard deviation) is greater than the market's average. For our test, we assume the market's quarterly standard deviation is 10%.
Our test will examine quarterly returns over the past five years, so n = 20, and degrees of freedom = 19. Our test is a greater-than test with the null hypothesis of σ2 < (10)2, or 100, and an alternate hypothesis of σ2 > 100. Using a 0.05 level of significance, our rejection point, from the chi-square tables with df = 19 and p = 0.05 in the right tail, is 30.144. Thus if our calculated test statistic is greater than 30.144, we reject the null hypothesis at 5% level of significance.
Answer: Examining the quarterly returns for this period, we find our sample variance (s2) is 135. With n = 20 and σ02 = 100, we have all the data required to calculate the test statistic.
χ2 = ((n - 1)*s2)/σ02 = ((20 - 1)*135)/100 = 2565/100 or 25.65.
Since 25.65 is less than our critical value of 30.144, we do not have enough evidence to reject the null hypothesis. While this fund may indeed be quite volatile, its volatility isn't statistically more meaningful than the market average for the period.
Hypothesis Tests Relating to the equality of the Variances of Two Normally Distributed Populations, where both Samples are Random and Independent
For hypothesis tests concerning relative values of the variances from two populations - whether σ12 (variance of the first population) and σ22 (variance of the second) are equal/not equal/greater than/less than - we can construct hypotheses in one of three ways.
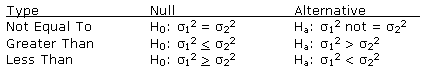 |
When a hypothesis test compares variances from two populations and we can assume that random samples from the populations are independent (uncorrelated), the appropriate test is the F-test, which represents the ratio of sample variances. As with the chi-square, the F-distribution is a family of asymmetrical distributions (bound on the left by zero). The F-family of distributions is defined by two values of degrees of freedom: the numerator (df1) and denominator (df2). Each of the degrees of freedom are taken from the sample sizes (each sample size - 1).
The F-test taken from the sample data could be either s12/s22, or s22/s12 - with the convention to use whichever ratio produces the larger number. This way, the F-test need only be concerned with values greater than 1, since one of the two ratios is always going to be a number above 1.
Example: Hypothesis Testing w/ Ratio of Sample Variances
To illustrate, take a case of two mutual funds. Fund A has enjoyed greater performance returns than Fund B (which we've owned, unfortunately). Our hypothesis is that the level of risk between these two is actually quite similar, meaning the Fund A has superior risk-adjusted results. We test the hypothesis for the past five years of quarterly data (df is 19 for both numerator and denominator). Using 0.05 significance, our critical value from the F-tables is 2.51. Assume from the five-year sample that quarterly standard deviations have been 8.5 for Fund A, and 6.3 for Fund B.
Answer: Our F-statistic is (8.5)2/(6.3)2 = 72.25/39.69 = 1.82.
Since 1.82 does not reach the rejection level of 2.51, we cannot reject the null hypothesis, and we state that the risk between these funds is not significantly different.
Concepts from the hypothesis-testing section are unlikely to be tested by rigorous exercises in number crunching but rather in identifying the unique attributes of a given statistic. For example, a typical question might ask, "In hypothesis testing, which test statistic is defined by two degrees of freedom, the numerator and the denominator?", giving you these choices: A. t-test, B. z-test, C. chi-square, or D. F-test. Of course, the answer would be D. Another question might ask, "Which distribution is NOT symmetrical?", and then give you these choices: A. t, B. z, C. chi-square, D. normal. Here the answer would be C. Focus on the defining characteristics, as they are the most likely source of exam questions.
Parametric and Nonparametric Tests
All of the hypothesis tests described thus far have been designed, in one way or another, to test the predicted value of one or more parameters - unknown variables such as mean and variance that characterize a population and whose observed values are distributed in a certain assumed way. Indeed, these specific assumptions are mandatory and also very important: most of the commonly applied tests are built with data that assumes the underlying population is normally distributed, which if not true, invalidates the conclusions reached. The less normal the population (i.e. the more skewed the data), the less these parametric tests or procedures should be used for the intended purpose.
Nonparametric
hypothesis tests are designed for cases where either (a) fewer or different assumptions about the population data are appropriate, or (b) where the hypothesis test is not concerned with a population parameter.
In many cases, we are curious about a set of data but believe that the required assumptions (for example, normally distributed data) do not apply to this example, or else the sample size is too small to comfortably make such an assumption. A number of nonparametric alternatives have been developed to use in such cases. The table below indicates a few examples that are analogous to common parametric tests.
| Concern of hypothesis | Parametric test | Nonparametric |
| Single mean | t-test, z-test | Wilcoxian signed-rank test |
| Differences between means | t-test (or approximate t-test) | Mann-Whitney U-test |
| Paired comparisons | t-test | Sign test, or Wilcoxian |
Source: DeFusco, McLeavey, Pinto, Runkle, Quantitative Methods for Investment Analysis, 2nd edition, Chapter 7, p 357. | ||
A number of these tests are constructed by first converting data into ranks (first, second, third, etc.) and then fitting the data into the test. One such test applied to testing correlation (the degree to which two variables are related to each other) is the Spearman rank correlation coefficient. The Spearman test is useful in cases where a normal distribution cannot be assumed - usually when a variable is bound by zero (always positive), or where the range of values are limited. For the Spearman test, each observation in the two variables is ranked from largest to smallest, and then the differences between the ranks are measured. The data is then used to find the test statistic rs: 1 - [6*(sum of squared differences)/n*(n2 - 1)]. This result is compared to a rejection point (based on the Spearman rank correlation) to determine whether to reject or not reject the null hypothesis.
Another situation requiring a nonparametric approach is to answer a question about something other than a parameter. For example, analysts often wish to address whether a sample is truly random or whether the data have a pattern indicating that it is not random (tested with the so-called "runs test"). Tests such as Kolmogorov-Smirnov find whether a sample comes from a population that is distributed a certain way. Most of these nonparametric examples are specialized and unlikely to be tested in any detail on the CFA Level I exam.
(See more) Correlation and Regression




0 comments:
Post a Comment