
Financial variables are often analyzed for their correlation to other variables and/or market averages. The relative degree of co-movement can serve as a powerful predictor of future behavior of that variable. A sample covariance and correlation coefficient are tools used to indicate relation, while a linear regression is a technique designed both to quantify a positive relationship between random variables, and prove that one variable is dependent on another variable. When you are analyzing a security, if returns are found to be significantly dependent on a market index or some other independent source, then both return and risk can be better explained and understood.
Scatter Plots
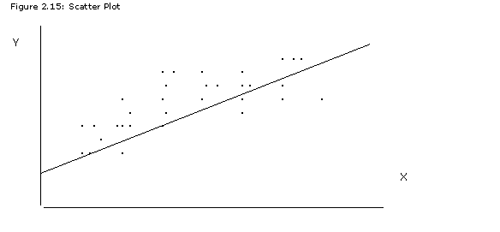
A scatter plot is designed to show a relationship between two variables by graphing a series of observations on a two-dimensional graph - one variable on the X-axis, the other on the Y-axis.
Figure 2.15: Scatter Plot
 |
Sample Covariance
To quantify a linear relationship between two variables, we start by finding the covariance of a sample of paired observations. A sample covariance between two random variables X and Y is the average value of the cross-product of all observed deviations from each respective sample mean. A cross-product, for the ith observation in a sample, is found by this calculation: (ith observation of X - sample mean of X) * (ith observation of Y - sample mean of Y). The covariance is the sum of all cross-products, divided by (n - 1).
To illustrate, take a sample of five paired observations of annual returns for two mutual funds, which we will label X and Y:
Year | X return | Y return | Cross-Product: (Xi - Xmean)*(Yi - Ymean) |
1st | +15.5 | +9.6 | (15.5 - 6.6)*(9.6 - 7.3) = 20.47 |
2nd | +10.2 | +4.5 | (10.2 - 6.6)*(4.5 - 7.3) = -10.08 |
3rd | -5.2 | +0.2 | (-5.2 - 6.6)*(0.2 - 7.3) = 83.78 |
4th | -6.3 | -1.1 | (-6.3 - 6.6)*(-1.1 - 7.3) = 108.36 |
5th | +12.7 | +23.5 | (12.7 - 6.6)*(23.5 - 7.3) = 196.02 |
Sum | 32.9 | 36.7 | 398.55 |
Average | 6.6 | 7.3 | 398.55/(n - 1) = 99.64 = Cov (X,Y) |
Average X and Y returns were found by dividing the sum by n or 5, while the average of the cross-products is computed by dividing the sum by n - 1, or 4. The use of n - 1 for covariance is done by statisticians to ensure an unbiased estimate.
Interpreting a covariance number is difficult for those who are not statistical experts. The 99.64 we computed for this example has a sign of "returns squared" since the numbers were percentage returns, and a return squared is not an intuitive concept. The fact that Cov(X,Y) of 99.64 was greater than 0 does indicate a positive or linear relationship between X and Y. Had the covariance been a negative number, it would imply an inverse relationship, while 0 means no relationship. Thus 99.64 indicates that the returns have positive co-movement (when one moves higher so does the other), but doesn't offer any information on the extent of the co-movement.
Sample Correlation CoefficientBy calculating a correlation coefficient, we essentially convert a raw covariance number into a standard format that can be more easily interpreted to determine the extent of the relationship between two variables. The formula for calculating a sample correlation coefficient (r) between two
random variables X and Y is the following:
| Formula 2.39 r = (covariance between X, Y) / (sample standard deviation of X) * (sample std. dev. of Y). |
Example: Correlation Coefficient
Return to our example from the previous section, where covariance was found to be 99.64. To find the correlation coefficient, we must compute the sample variances, a process illustrated in the table below.
Year | X return | Y return | Squared X deviations | Squared Y deviations |
1st | +15.5 | +9.6 | (15.5 - 6.6)2 = 79.21 | (9.6 - 7.3)2 = 5.29 |
2nd | +10.2 | +4.5 | (10.2 - 6.6)2 = 12.96 | (4.5 - 7.3)2 = 7.84 |
3rd | -5.2 | +0.2 | (-5.2 - 6.6)2 = 139.24 | (0.2 - 7.3)2 = 50.41 |
4th | -6.3 | -1.1 | (-6.3 - 6.6)2 = 166.41 | (-1.1 - 7.3)2 = 70.56 |
5th | +12.7 | +23.5 | (12.7 - 6.6)2 = 146.41 | (23.5 - 7.3)2 = 262.44 |
Sum | 32.9 | 36.7 | 544.23 | 369.54 |
Average | 6.6 | 7.3 | 136.06 = X variance | 99.14 = Y variance |
Answer:
As with sample covariance, we use (n - 1) as the denominator in calculating sample variance (sum of squared deviations as the numerator) - thus in the above example, each sum was divided by 4 to find the variance. Standard deviation is the positive square root of variance: in this example, sample standard deviation of X is (136.06)1/2, or 11.66; sample standard deviation of Y is (99.14)1/2, or 9.96.
Therefore, the correlation coefficient is (99.64)/11.66*9.96 = 0.858. A correlation coefficient is a value between -1 (perfect inverse relationship) and +1 (perfect linear relationship) - the closer it is to 1, the stronger the relationship. This example computed a number of 0.858, which would suggest a strong linear relationship.
Hypothesis Testing: Determining Whether a Positive or Inverse Relationship Exists Between Two Random Variables
A hypothesis-testing procedure can be used to determine whether there is a positive relationship or an inverse relationship between two random variables. This test uses each step of the hypothesis-testing procedure, outlined earlier in this study guide. For this particular test, the null hypothesis, or H0, is that the correlation in the population is equal to 0. The alternative hypothesis, Ha, is that the correlation is different from 0. The t-test is the appropriate test statistic. Given a sample correlation coefficient r, and sample size n, the formula for the test statistic is this:
t = r*(n - 2)1/2/(1 - r2)1/2, with degrees of freedom = n - 2 since we have 2 variables.
Testing whether a correlation coefficient is equal/not equal to 0 is a two-tailed test. In our earlier example with a sample of 5, degrees of freedom = 5 - 2 = 3, and our rejection point from the t-distribution, at a significance level of 0.05, would be 3.182 (p = 0.025 for each tail).
Using our computed sample r of 0.858, t = r*(n - 2)1/2/(1 - r2)1/2 = (0.858)*(3)1/2/(1 - (0.858)2)1/2 = (1.486)/(0.514) = 2.891. Comparing 2.891 to our rejection point of 3.182, we do not have enough evidence to reject the null hypothesis that the population correlation coefficient is 0. In this case, while it does appear that there is a strong linear relationship between our two variables (and thus we may well be risking a type II error), the results of the hypothesis test show the effects of a small sample size; that is, we had just three degrees of freedom, which required a high rejection level for the test statistic in order to reject the null hypothesis. Had there been one more observation on our sample (i.e. degrees of freedom = 4), then the rejection point would have been 2.776 and we would have rejected the null and accepted that there is likely to be a significant difference from 0 in the population r. In addition, level of significance plays a role in this hypothesis test. In this particular example, we would reject the null hypothesis at a 0.1 level of significance, where the rejection level would be any test statistic higher than 2.353.
Of course, a hypothesis-test process is designed to give information about that example and the pre-required assumptions (done prior to calculating the test statistic). Thus it would stand that the null could not be rejected in this case. Quite frankly, the hypothesis-testing exercise gives us a tool to establish significance to a sample correlation coefficient, taking into account the sample size. Thus, even though 0.858 feels close to 1, it's also not close enough to make conclusions about correlation of the underlying populations - with small sample size probably a factor in the test.
(See more) Regression Analysis




0 comments:
Post a Comment