
Hypothesis testing provides a basis for taking ideas or theories that someone initially develops about the economy or investing or markets, and then deciding whether these ideas are true or false.
More precisely, hypothesis testing helps decide whether the tested ideas are probably true or probably false as the conclusions made with the hypothesis-testing process are never made with 100% confidence - which we found in the sampling and estimating process: we have degrees of confidence - e.g. 95% or 99% - but not absolute certainty.
Hypothesis testing is often associated with the procedure for acquiring and developing knowledge known as the scientific method. As such, it relates the fields of investment and economic research (i.e., business topics) to other traditional branches of science (mathematics, physics, medicine, etc.)
Hypothesis testing is similar in some respects to the estimation processes presented in the previous section. Indeed, the field of statistical inference, where conclusions on a population are drawn from observing subsets of the larger group, is generally divided into two groups: estimation and hypothesis testing.
With estimation, the focus was on answering (with a degree of confidence) the value of a parameter, or else a range within which the parameter most likely falls. Think of estimating as working from general to specific. With hypothesis testing, the focus is shifted: we start my making a statement about the parameter's value, and then the question becomes whether the statement is true or not true. In other words, it starts with a specific value and works the other way to make a general statement.
What is a Hypothesis?
A hypothesis is a statement made about a population parameter. These are typical hypotheses: "the mean annual return of this mutual fund is greater than 12%", and "the mean return is greater than the average return for the category". Stating the hypothesis is the initial step in a defined seven-step process for hypothesis testing - a process developed based on the scientific method. We indicate each step below. In the remainder of this section of the study guide, we develop a detailed explanation for how to answer each step's question.
Hypothesis testing seeks to answer seven questions:
- What are the null hypothesis and the alternative hypothesis?
- Which test statistic is appropriate, and what is the probability distribution?
- What is the required level of significance?
- What is the decision rule?
- Based on the sample data, what is the value of the test statistic?
- Do we reject or fail to reject the null hypothesis?
- Based on our rejection or inability to reject, what is our investment or economic decision?
Step #1 in our process involves stating the null and alternate hypothesis. The null hypothesis is the statement that will be tested. The null hypothesis is usually denoted with "H0". For investment and economic research applications, and as it relates to the CFA exam, the null hypothesis will be a statement on the value of a population parameter, usually the mean value if a question relates to return, or the standard deviation if it relates to risk. It can also refer to the value of any random variable (e.g. sales at company XYZ are at least $10 million this quarter). In hypothesis testing, the null hypothesis is initially regarded to be true, until (based on our process) we gather enough proof to either reject the null hypothesis, or fail to reject the null hypothesis.
Alternative Hypothesis
The alternative hypothesis is a statement that will be accepted as a result of the null hypothesis being rejected. The alternative hypothesis is usually denoted "Ha". In hypothesis testing, we do not directly test the worthiness of the alternate hypothesis, as our testing focus is on the null.
Think of the alternative hypothesis as the residual of the null - for example, if the null hypothesis states that sales at company XYZ are at least $10 million this quarter, the alternative hypothesis to this null is that sales will fail to reach the $10 million mark.
Between the null and the alternative, it is necessary to account for all possible values of a parameter. In other words, if we gather evidence to reject this null hypothesis, then we must necessarily accept the alternative. If we fail to reject the null, then we are rejecting the alternative.
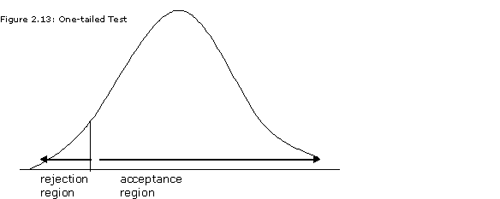
One-Tailed Test
The labels "one-tailed" and "two-tailed" refer to the standard normal distribution (as well as all of the t-distributions). The key words for identifying a one-tailed test are "greater than or less than". For example, if our hypothesis is that the annual return on this mutual fund will be greater than 8%, it's a one-tailed test that will be rejected based only on finding observations in the left tail.
Figure 2.13 below illustrates a one-tailed test for "greater than" (rejection in left tail). (A one-tailed test for "less than" would look similar to the graph below, with the rejection region for less than in the right tail rather than the left.)
 |
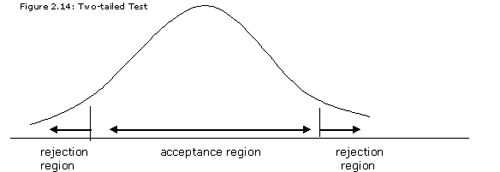
Two-Tailed test
Characterized by the words "equal to or not equal to". For example, if our hypothesis were that the return on a mutual fund is equal to 8%, we could reject it based on observations in either tail (sufficiently higher than 8% or sufficiently lower than 8%).
 |
Choosing the null and the alternate hypothesis:
If θ (theta) is the actual value of a population parameter (e.g. mean or standard deviation), and θ0 (theta subzero) is the value of theta according to our hypothesis, the null and alternative hypothesis can be formed in three different ways:
 |
Choosing what will be the null and what will be the alternative depends on the case and what it is we wish to prove. We usually have two different approaches to what we could make the null and alternative, but in most cases, it's preferable to make the null what we believe we can reject, and then attempt to reject it.
For example, in our case of a one-tailed test with the return hypothesized to be greater than 8%, we could make the greater-than case the null (alternative being less than), or we could make the greater-than case the alternative (with less than the null).
Which should we choose? A hypothesis test is typically designed to look for evidence that may possibly reject the null. So in this case, we would make the null hypothesis "the return is less than or equal to 8%", which means we are looking for observations in the left tail. If we reject the null, then the alternative is true, and we conclude the fund is likely to return at least 8%.
Test Statistic
Step #2 in our seven-step process involves identifying an appropriate test statistic. In hypothesis testing, a test statistic is defined as a quantity taken from a sample that is used as the basis for testing the null hypothesis (rejecting or failing to reject the null).
Calculating a test statistic will vary based upon the case and our choice of probability distribution (for example, t-test, z-value). The general format of the calculation is:
| Formula 2.36 Test statistic = (sample statistic) - (value of parameter according to null) (Standard error of sample statistic) |
Type I and Type II Errors
Step #3 in hypothesis testing involves specifying the significance level of our hypothesis test. The significance level is similar in concept to the confidence level associated with estimating a parameter - both involve choosing the probability of making an error (denoted by α, or alpha), with lower alphas reducing the percentage probability of error. In the case of estimators, the tradeoff of reducing this error was to accept a wider (less precise) confidence interval. In the case of hypothesis testing, choosing lower alphas also involves a tradeoff - in this case, increasing a second type of error.
Errors in hypothesis testing come in two forms: Type I and Type II. A type I error is defined as rejecting the null hypothesis when it is true. A type II error is defined as not rejecting the null hypothesis when it is false. As the table below indicates, these errors represent two of the four possible
outcomes of a hypothesis test:
 |
The reason for separating type I and type II errors is that, depending on the case, there can be serious consequences for a type I error, and there are other cases when type II errors need to be avoided, and it is important to understand which type is more important to avoid.
Significance Level
Denoted by α, or alpha, the significance level is the probability of making a type I error, or the probability that we will reject the null hypothesis when it is true. So if we choose a significance level of 0.05, it means there is a 5% chance of making a type I error. A 0.01 significance level means there is just a 1% chance of making a type I error. As a rule, a significance level is specified prior to calculating the test statistic, as the analyst conducting the research may use the result of the test statistic calculation to impact the choice of significance level (may prompt a change to higher or lower significance). Such a change would take away from the objectivity of the test.
While any level of alpha is permissible, in practice there is likely to be one of three possibilities for significance level: 0.10 (semi-strong evidence for rejecting the null hypothesis), 0.05 (strong evidence), and 0.01 (very strong evidence). Why wouldn't't we always opt for 0.01 or even lower probabilities of type I errors - isn't the idea to reduce and eliminate errors? In hypothesis testing, we have to control two types of errors, with a tradeoff that when one type is reduced, the other type is increased. In other words, by lowering the chances of a type I error, we must reject the null less frequently - including when it is false (a type II error). Actually quantifying this tradeoff is impossible because the probability of a type II error (denoted by β, or beta) is not easy to define (i.e. it changes for each value of θ). Only by increasing sample size can we reduce the probability of both types of errors.
Decision Rule
Step #4 in the hypothesis-testing process requires stating a decision rule. This rule is crafted by comparing two values: (1) the result of the calculated value of the test statistic, which we will complete in step #5 and (2) a rejection point, or critical value (or values) that is (are) the function of our significance level and the probability distribution being used in the test. If the calculated value of the test statistic is as extreme (or more extreme) than the rejection point, then we reject the null hypothesis, and state that the result is statistically significant. Otherwise, if the test statistic does not reach the rejection point, then we cannot reject the null hypothesis and we state that the result is not statistically significant. A rejection point depends on the probability distribution, on the chosen alpha, and on whether the test in one-tailed or two-tailed.
For example, if in our case we are able to use the standard normal distribution (the z-value), if we choose an alpha of 0.05, and we have a two-tailed test (i.e. reject the null hypothesis when the test statistic is either above or below), the two rejection points are taken from the z-values for standard normal distributions: below -1.96 and above +1.96. Thus if the calculated test statistic is in these two rejection ranges, the decision would be to reject the null hypothesis. Otherwise, we fail to reject the null hypothesis.
| Look Out! Traditionally, it was said that we accepted the null hypothesis; however, the authors have discouraged use of the word "accept", in terms of accepting the null hypothesis, as those terms imply a greater degree of conviction about the null than is warranted. Having made the effort to make this distinction, do not be surprised if this subtle change (which seems inconsequential on the surface) somehow finds its way onto the CFA exam (if you answer "accept the null hypothesis", you get the question wrong, and if you answer "fail to reject the null hypothesis" you score points. |
Power of a Test
The power of a hypothesis test refers to the probability of correctly rejecting the null hypothesis. There are two possible outcomes when the null hypothesis is false: either we (1) reject it (as we correctly should) or (2) we accept it - and make a type II error. Thus the power of a test is also equivalent to 1 minus the beta (β), the probability of a type II error. Since beta isn't quantified, neither is the power of a test. For hypothesis tests, it is sufficient to specify significance level, or alpha. However, given a choice between more than one test statistic (for example, z-test, t-test), we will always choose the test that increases a test's power, all other factors equal.
Confidence Intervals vs. Hypothesis Tests
Confidence intervals, as a basis for estimating population parameters, were constructed as a function of "number of standard deviations away from the mean". For example, for 95% confidence that our interval will include the population mean (μ), when we use the standard normal distribution (z-statistic), the interval is: (sample mean) ± 1.96 * (standard error), or, equivalently,-1.96*(standard error) < (sample mean) < +1.96*(standard error).
Hypothesis tests, as a basis for testing the value of population parameters, are also set up to reject or not reject based on "number of standard deviations away from the mean". The basic structure for testing the null hypothesis at the 5% significance level, again using the standard normal, is -1.96 < [(sample mean - hypothesized population mean) / standard error] < +1.96, or, equivalently,-1.96 * (std. error) < (sample mean) - (hypo. pop. mean) < +1.96 * (std. error).
In hypothesis testing, we essentially create an interval within which the null will not be rejected, and we are 95% confident in this interval (i.e. there's a 5% chance of a type I error). By slightly rearranging terms, the structure for a confidence interval and the structure for rejecting/not rejecting a null hypothesis appear very similar - an indication of the relationship between the concepts.
Making a Statistical Decision
Step #6 in hypothesis testing involves making the statistical decision, which actually compares the test statistic to the value computed as the rejection point; that is, it carries out the decision rule created in step #4. For example, with a significance level of 0.05, using the standard normal distribution, on a two-tailed test (i.e. null is "equal to"; alternative is not equal to), we have rejection points below -1.96 and above +1.96. If our calculated test statistic
[(sample mean - hypothesized mean) / standard error] = 0.6, then we cannot reject the null hypothesis. If the calculated value is 3.6, we reject the null hypothesis and accept the alternative.
The final step, or step #7, involves making the investment or economic decision (i.e. the real-world decision). In this context, the statistical decision is but one of many considerations. For example, take a case where we created a hypothesis test to determine whether a mutual fund outperformed its peers in a statistically significant manner. For this test, the null hypothesis was that the fund's mean annual return was less than or equal to a category average; the alternative was that it was greater than the average.
Assume that at a significance level of 0.05, we were able to establish statistical significance and reject the null hypothesis, thus accepting the alternative. In other words, our statistical decision was that this fund would outperform peers, but what is the investment decision?
The investment decision would likely take into account (for example) the risk tolerance of the client and the volatility (risk) measures of the fund, and it would assess whether transaction costs and tax implications make the investment decision worth making.
In other words, rejecting/not rejecting a null hypothesis does not automatically require that a decision be carried out; thus there is the need to assess the statistical decision and the economic or investment decision in two separate steps.
(See more) Interpreting Statistical Results




0 comments:
Post a Comment